我相信现在同时喜欢读博客并且喜欢数学的人已经不多了。如果你恰好在这个圈子里面,你或许听说过 matrix67 这个人。他的博客 The Aha Moments 用简单易懂的语言讲述了许多有趣的数学问题。你或许不知,matrix67 还开发了一个叫 ideagen 的神秘板块,专门用来启发思维。这个 idea generator 的工作机制十分简单,每当你刷新页面的时候,它就会返回一个新的短语。只要稍加测试即可发现,这个东西返回的大部分结果都很无厘头,一小部分结果如果脑洞够大,还是有些意义的。这是我在五次测试中拿到的短语:
1 | 合意的老处女 |
这些短语有明显的共性,都是一个名词跟在一个形容词后面。无厘头的结果,加上固定的模式,不难使人想到这些短语不是直接采集自语料库,而是由语料库中的形容词和名词随机拼接而成的。为了验证这个猜想,我设计了如下的实验。
抓取一百万个短语,利用形容词后缀“的”这个字拆分形容词和名词部分,分别统计两部分各词组出现频率的分布。如果这两个分布均为正态分布,则在下列假设成立的前提下,我们可以认为这个短语是由相互独立的两个随机词组拼接而成的:
- 形容词的数量远小于一百万
- 名词的数量远小于一百万
- 形容词和名词之间没有特殊的对应关系
理论上说,通过抽样验证两个随机变量之间的相互独立性,应当考察其联合概率分布是否服从联合正态分布。而在我们的假设下,若形容词和名词的选取过程相互独立,则联合分布的空间将会很大,在客观上无法通过实验验证。但在常识上,只要数据不是非常诡异,如形容词和名词间有一一对应的关系,则我们可以通过分别考察两个分布来推测其联合分布。
确定思路之后,实现整个实验并不困难。Python 的 urllib 提供了简单的接口用于发送 HTTP request 并查看 response. Beautiful Soup 提供了 HTML DOM 的解析功能,只需要一行代码即可直接定位这个短语。感谢 matrix67 使用了 UTF-8 而不是蛋疼的 GB2312, 让 Python3 可以毫无压力地解码字节串。经过 AWS 主机两天漫长的运行,我终于抓取了一百万个样本。其形容词和名词部分出现的频率分布直方图分别如同所示。

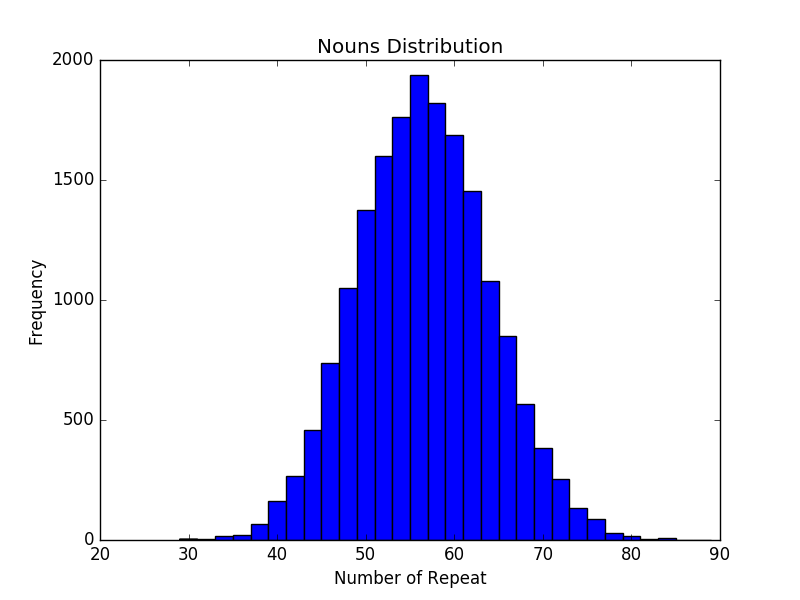
可以看出这两个变量都呈现出典型的正态分布图案。
为了进一步验证上述假设,我计算了抓取的形容词和名词个数,共发现了 967 个不同的形容词和 17834 个不同的名词。使用这些词组,按照随机抽样和随机组合的方式仿真了一百万次请求,所得的直方图如下所示。
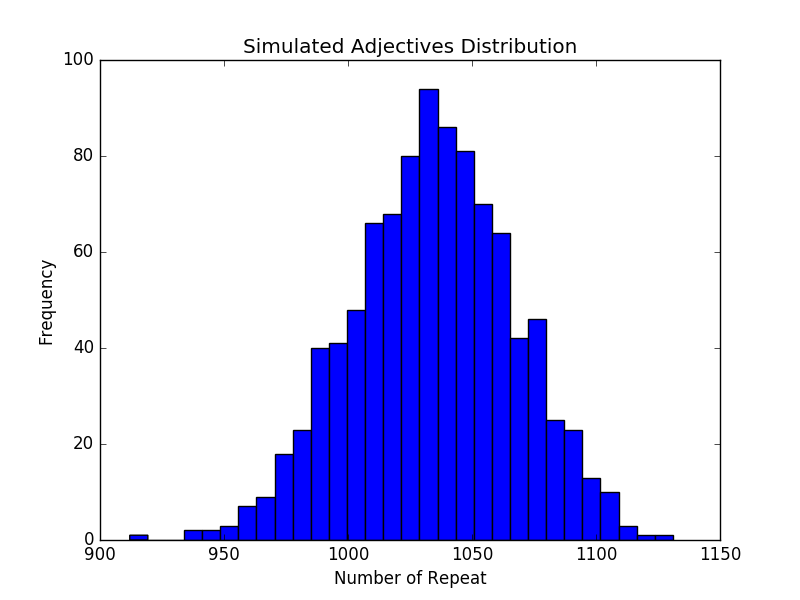
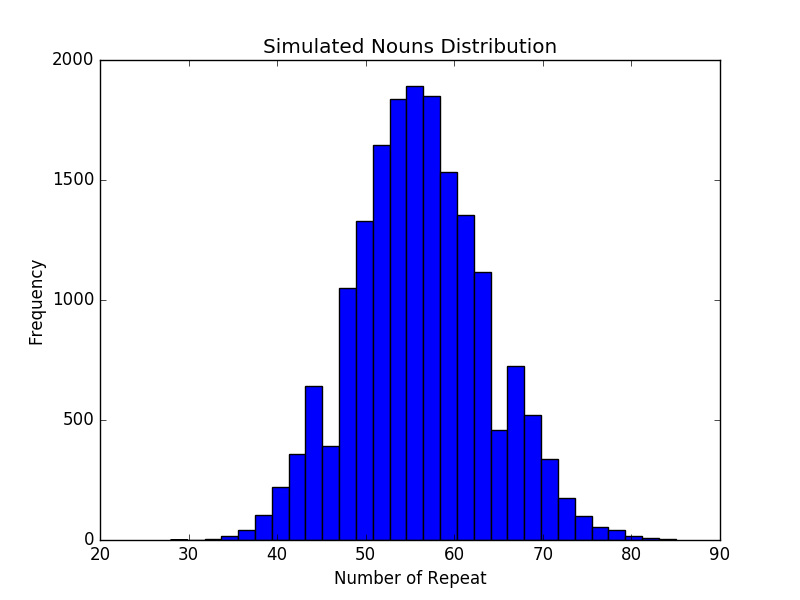
可以看出这两个直方图与实际数据的直方图十分接近,这说明独立随机抽样生成短语的方式,是产生上述实验结果的充分条件。根据这些事实,我们有理由相信独立随机抽样也是上述实验结果的充分条件,这就证实了最初的猜想。
整个实验的代码可在 GitHub Gist 上查阅(需翻墙)。运行这段代码需要至少 48 小时。如果你是 NLP 爱好者,想要获取本实验抓取的语料库,请联系我。
最后扯两句八卦,matrix67 的妻子也有一个博客,名曰 localhost. matrix67 的博客用的其实是他妻子开发的模板。后来我的某著名好友挖出来 localhost 本人是北理工校友,我们这才感慨,我理虽渣,终究还是出了几位怪才。另外这一对夫妻和另一对开博客的夫妻(我不记得了)被我的好友尊为“爱情的模范”。在此我也衷心祝愿大家(包括我自己……)找到真爱。